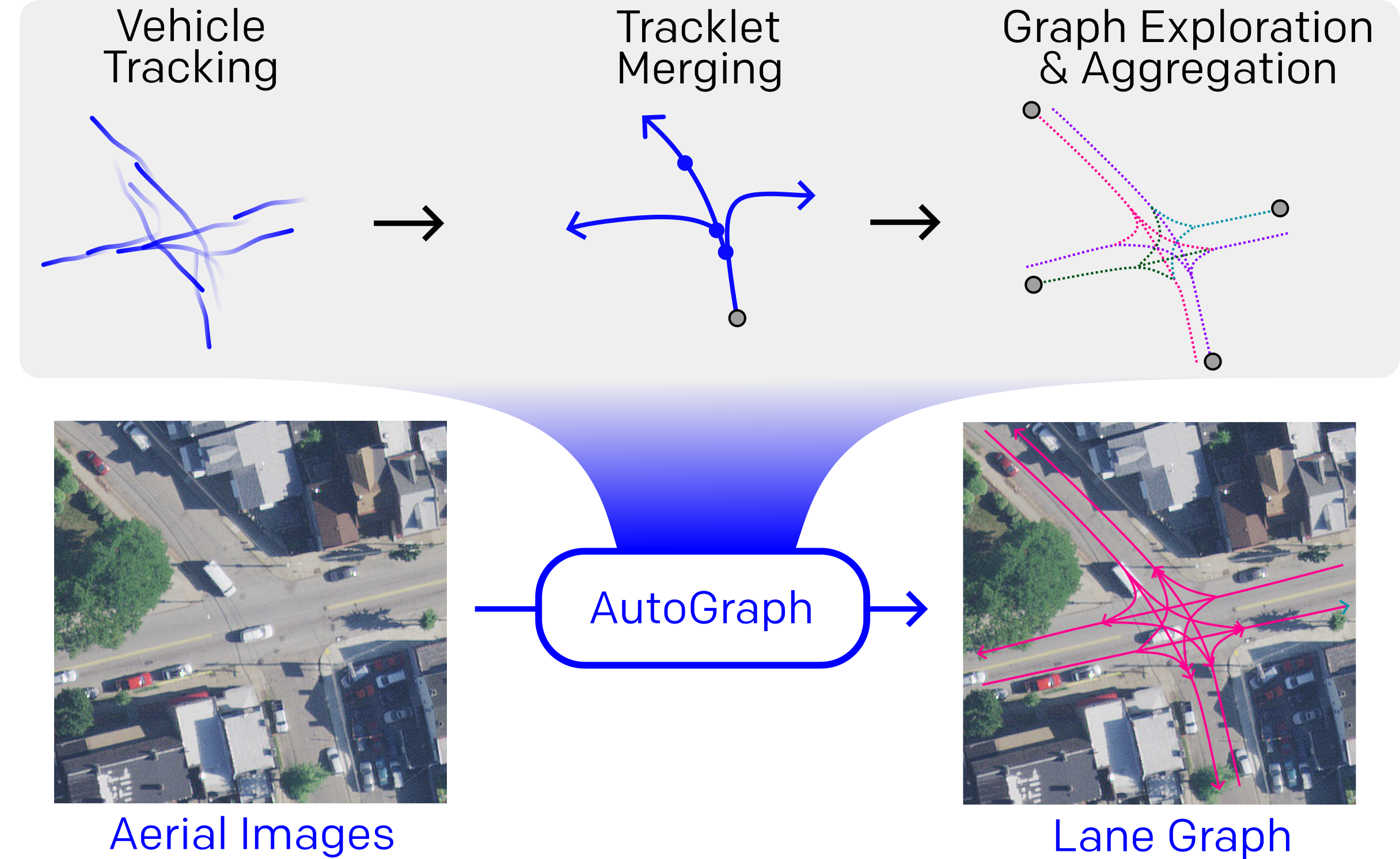
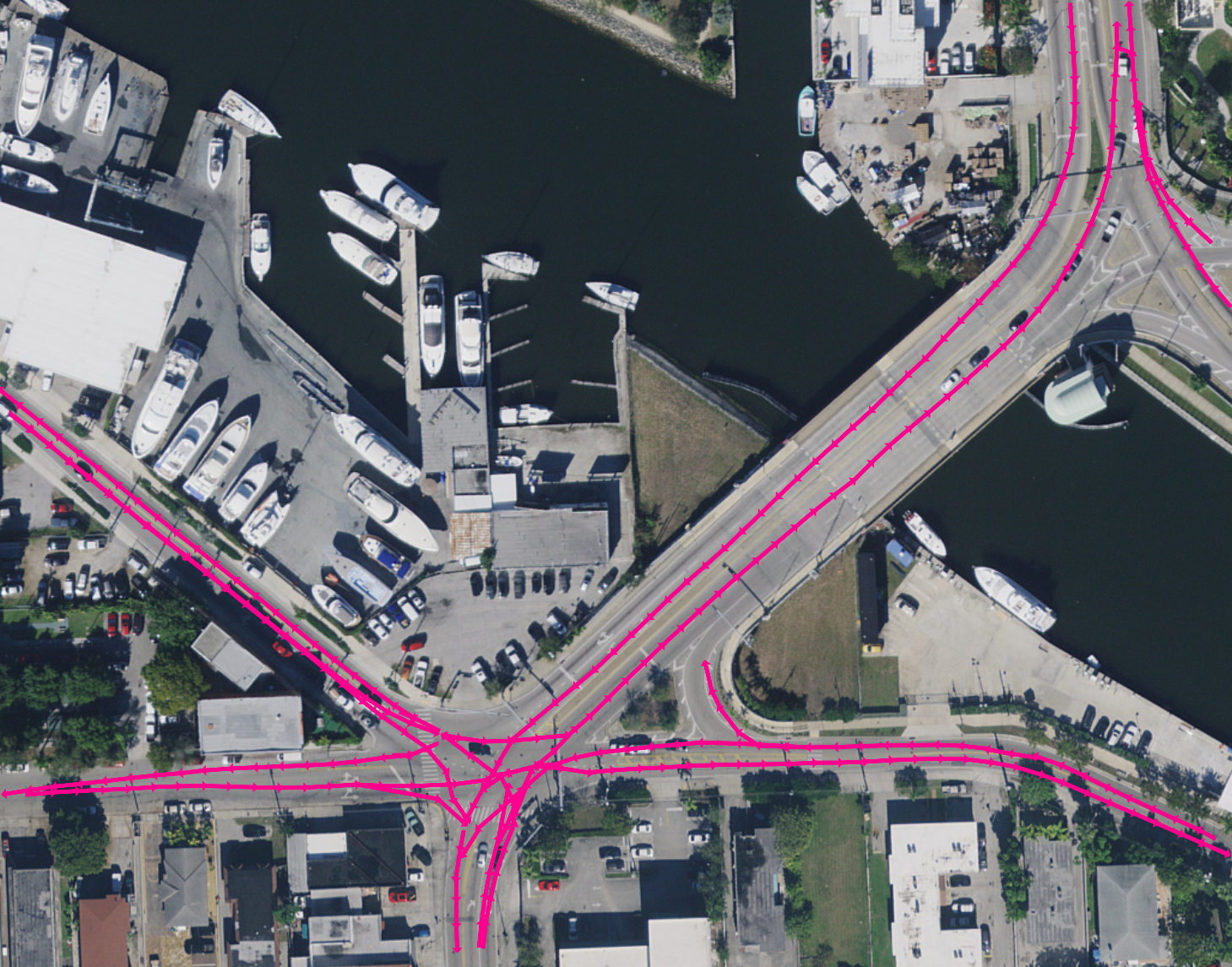
Our approach can be split into three distinct stages: First,
tracklet parsing and merging, where we track traffic participants through all scenes in the dataset and prepare the data
for model training. Second, model training, where we train
the proposed models with data obtained in the first stage.
Third, we perform inference with our trained models and
aggregate the graphs into a globally consistent representation.
In the following, we detail each component of our approach.
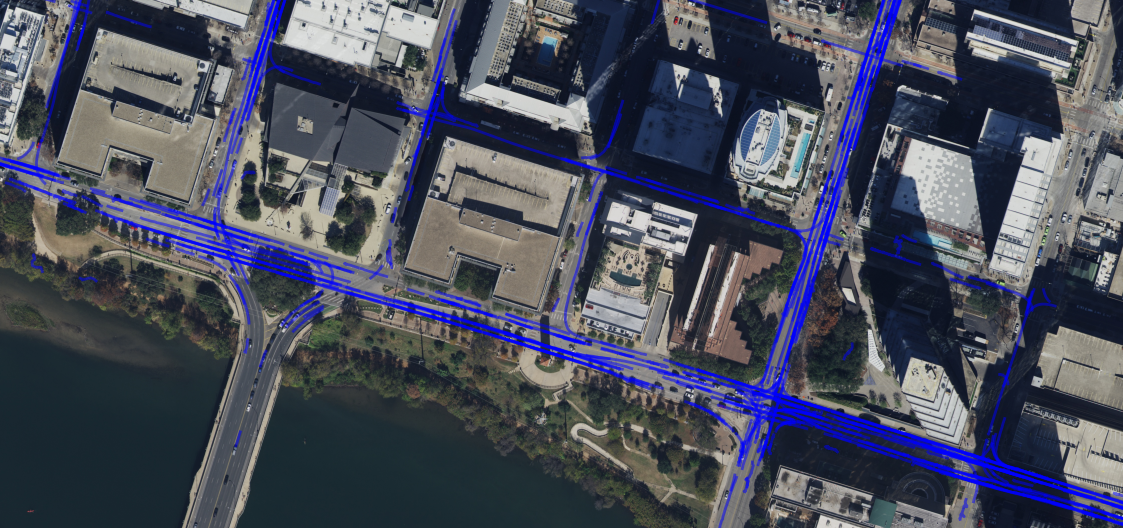
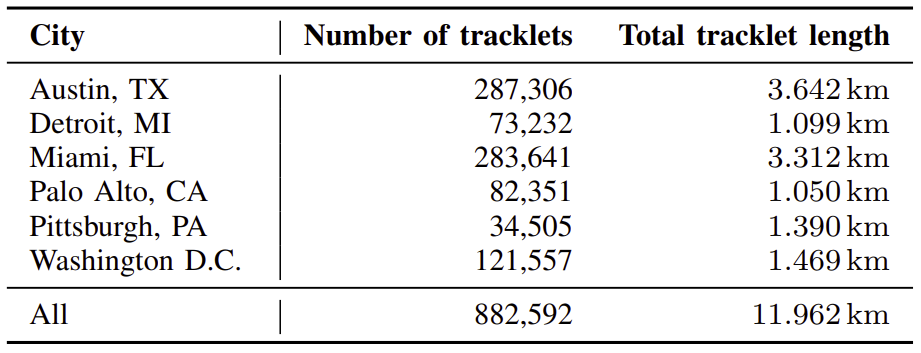
We start our data processing pipeline by tracking traffic participants in all available scenes of the Argoverse2
dataset across all six available cities. Each scene in the dataset consists of approximately 20 seconds of driving.
For each scene, we track vehicles such as cars, trucks, motorcycles, and busses using a pre-trained LiDAR-based
object detector. We transform all tracklets into a global
coordinate frame. Subsequently, we smooth the tracklets with
a moving average filter in order to minimize the amount
of observation noise and the influence of erradic driving
behavior (i.e. steering inaccuracies).
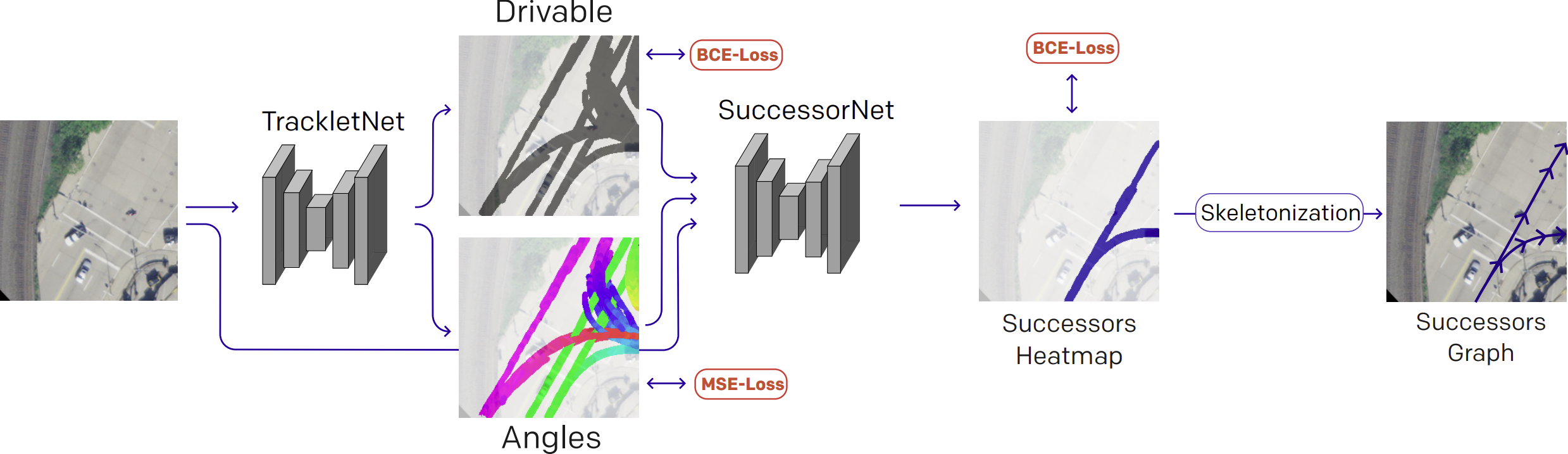
Successor Lane Graph Prediction
The whole training pipeline is visualized in the figure below. After
our aggregation step, we are able to query all tracklets that
are visible in an aerial image crop, starting from a given
querying position. To obtain a training dataset for our
models, for each query pose, we crop an aerial image from the aerial image,centered and oriented around
the query pose. In the same way, we crop and center the
drivable map and the angle map.
Our model consists of two sub-networks. As a first step,
we train a DeepLabv3+ model to predict the pixel-wise
drivable and angle maps from an RGB aerial image input. We denote this
model as TrackletNet. This initial task is identified as an
auxiliary task, leveraging the vast amount of tracklets readily
available for a given crop. For training, we use a binary
cross-entropy loss to guide the prediction of the drivable map
layer and a mean squared error loss for the prediction of
the angle map.
In the second step, we train a separate DeepLabv3+
model to predict the successor graph from a certain pose q,
which we parameterize as a heatmap. To account for
the additional Drivable and Angles input layers, we adapt
the number of input layers of the DeepLabv3+ model architecture. We denote this model as SuccessorNet. To obtain
per-pixel labeling of the successor graph in the image crop,
we render the successor graph as a heatmap in the crop by
drawing along the graph edges with a certain stroke width.
This heatmap highlights all regions in the aerial image that
are reachable by an agent placed at pose q. We train our
SuccessorNet model with a binary cross-entropy loss.
Finally, we skeletonize the predicted heatmap using a
morphological skinning process and convert the skeleton
into a graph representation.
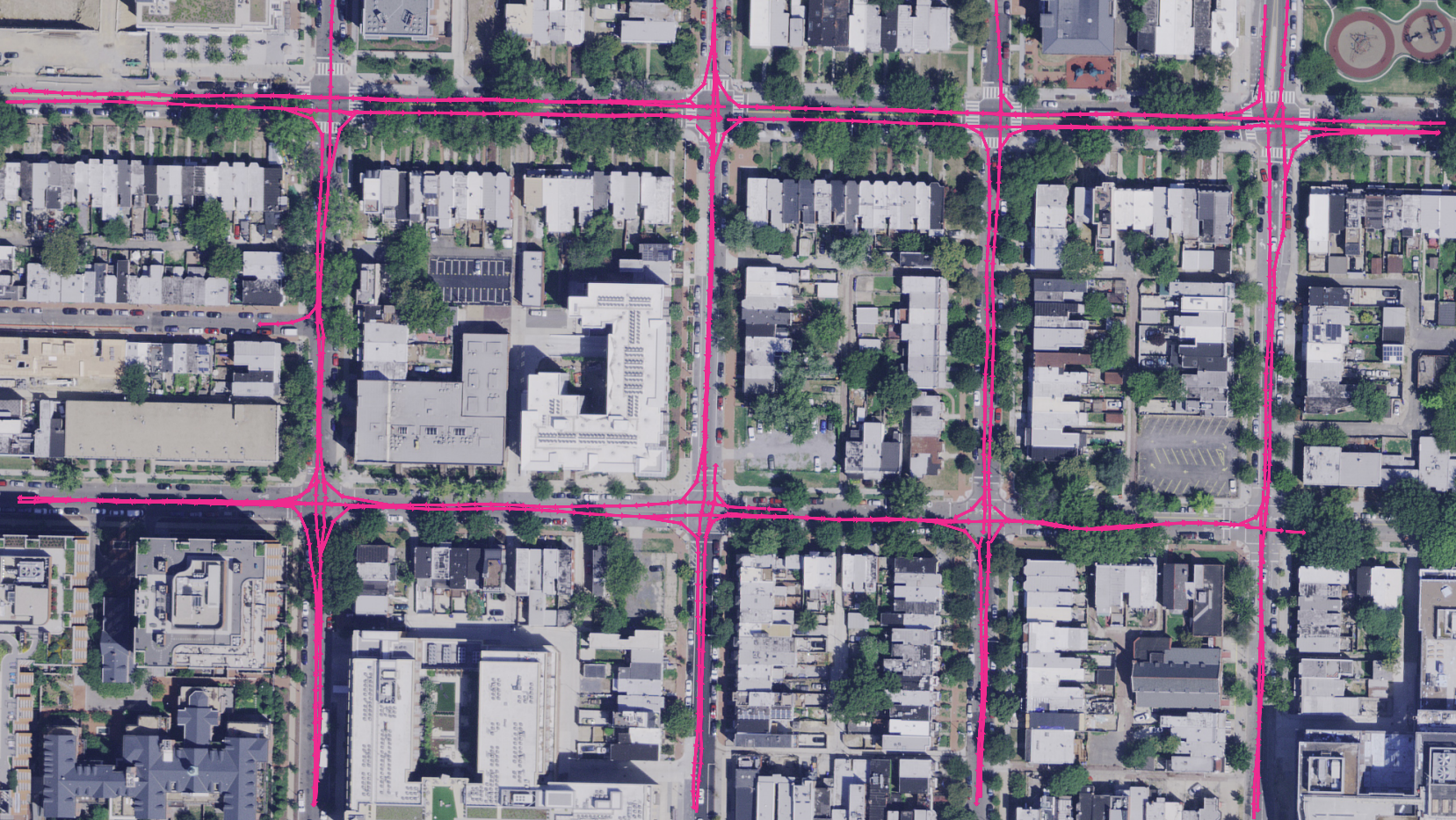
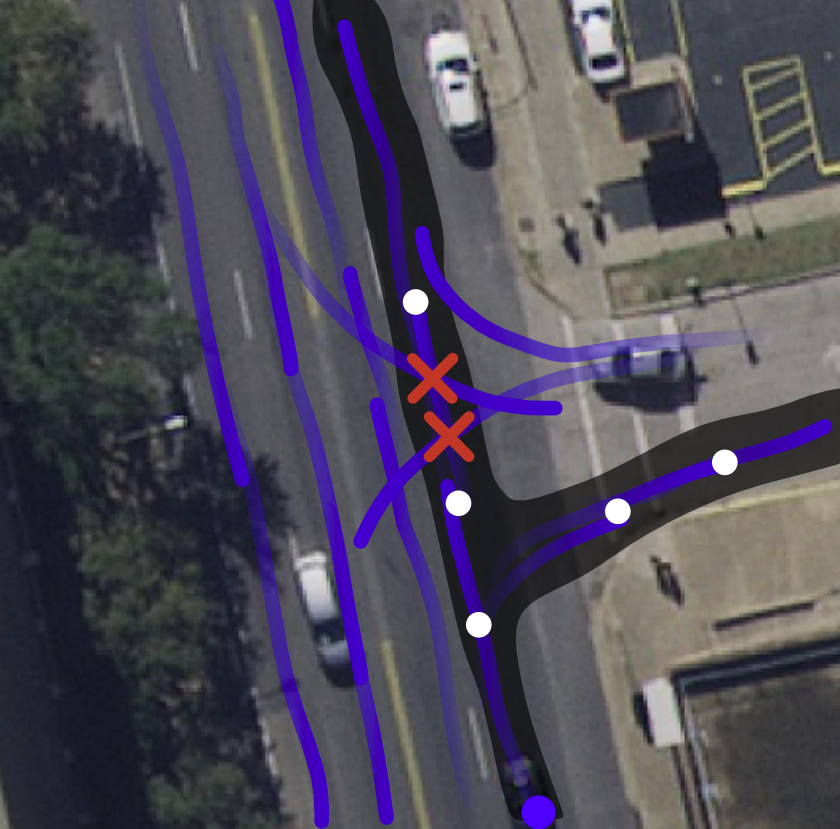
Graph Exploration and Aggregation
In this section, we illustrate how
a complete lane graph can be obtained from running our
AutoGraph model iteratively on its own predictions and
subsequently aggregating these predictions into a globally
consistent graph representation. To this end, we leverage a
depth-first exploration algorithm: We initialize our model by
selecting start poses, which can either be selected manually
or obtained from our TrackletNet model. We predict the
successor graph from this initial position and query our
model along the successor graph and repeat the process. In
the case of a straight road section, for each forward pass
of our model, a single future query pose is added to the
list of query poses to process. If a lane split is encountered,
for each of the successor subgraphs starting at lane splits, a
query pose is added to the list. If a lane ends or no successor
graphs are found, the respective branch of the aggregated
lane graph terminates and the next pose in the list is queried.
The exploration terminates once the list of future query poses
is empty.